AI爬虫大规模爬取网站内容,导致网站打不开,附解决方案 |
我要说一句
收起回复
| |
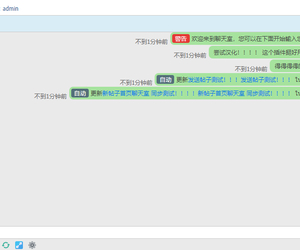 与dz-x.net同款首页聊天室最新汉化版本!!2619 人气#Discuz!插件模板
与dz-x.net同款首页聊天室最新汉化版本!!2619 人气#Discuz!插件模板 克米设计-滚动热图 v3.0.20210916(comiis_r2193 人气#Discuz!插件模板
克米设计-滚动热图 v3.0.20210916(comiis_r2193 人气#Discuz!插件模板![克米设计简约资讯 Discuz! X3.5 X5.0版本(comiis_jynews)[细胞模板 内置DIY X5.0新架构新技术模板]](https://static.dz-x.net/block/f6/f6d6ed93826ee4f0a1593a48975dcfe3.jpg) 克米设计简约资讯 Discuz! X3.5 X5.0版本(429 人气#Discuz!插件模板
克米设计简约资讯 Discuz! X3.5 X5.0版本(429 人气#Discuz!插件模板![资源下载/资源分享 4.0(xlwsq_down)[带付费手机版七牛组件扩展调用]](https://static.dz-x.net/block/07/07fdcfc78f3bdc9d87ce582981d1b6f5.jpg) 资源下载/资源分享 4.0(xlwsq_down)[带付费5212 人气#Discuz!插件模板
资源下载/资源分享 4.0(xlwsq_down)[带付费5212 人气#Discuz!插件模板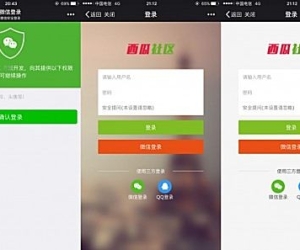 【西瓜】微信登录 83.9.2(xigua_login)2584 人气#Discuz!插件模板
【西瓜】微信登录 83.9.2(xigua_login)2584 人气#Discuz!插件模板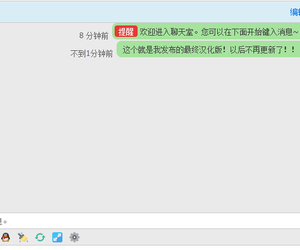 与dz-x.net同款首页聊天室 最终汉化版!3261 人气#Discuz!插件模板
与dz-x.net同款首页聊天室 最终汉化版!3261 人气#Discuz!插件模板
 /1
/1 
 加载中...
加载中...
 AI智能体
AI智能体

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



