阿里达摩院上线文本生成视频大模型:仅支持英文输入,已开放试玩 |
我要说一句
收起回复
| |
![资源下载/资源分享 4.0(xlwsq_down)[带付费手机版七牛组件扩展调用]](https://static.dz-x.net/block/07/07fdcfc78f3bdc9d87ce582981d1b6f5.jpg) 资源下载/资源分享 4.0(xlwsq_down)[带付费5165 人气#Discuz!插件模板
资源下载/资源分享 4.0(xlwsq_down)[带付费5165 人气#Discuz!插件模板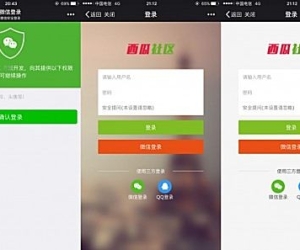 【西瓜】微信登录 83.9.2(xigua_login)2540 人气#Discuz!插件模板
【西瓜】微信登录 83.9.2(xigua_login)2540 人气#Discuz!插件模板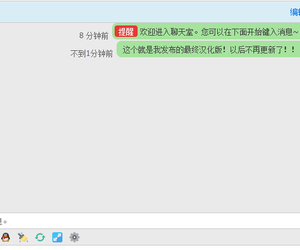 与dz-x.net同款首页聊天室 最终汉化版!3160 人气#Discuz!插件模板
与dz-x.net同款首页聊天室 最终汉化版!3160 人气#Discuz!插件模板 【转发分享】Discuz!添加一个新闻资讯页面102 人气#Discuz!插件模板
【转发分享】Discuz!添加一个新闻资讯页面102 人气#Discuz!插件模板![[狼码]个人博客 1.2.1(wolfcodeblog)](https://static.dz-x.net/block/7a/7ac94266632ad37dda984916735d4c6e.jpg) [狼码]个人博客 1.2.1(wolfcodeblog)1250 人气#Discuz!插件模板
[狼码]个人博客 1.2.1(wolfcodeblog)1250 人气#Discuz!插件模板 批量发帖 v3.7.2 商业版(nimba_threads)1033 人气#Discuz!插件模板
批量发帖 v3.7.2 商业版(nimba_threads)1033 人气#Discuz!插件模板
 /1
/1 
 加载中...
加载中...
 AI智能体
AI智能体

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



